Designing an effective API for AI-powered search is a non-trivial task, especially when the underlying system serves millions of users. At such a scale, considerations around latency, relevance, security, and extensibility become foundational. In this article, we explore key API design patterns that have emerged from building and operating large-scale AI search systems, offering practical guidance for engineering teams looking to deliver responsive, context-aware search experiences. Here’s what you’ll find in this article:
- Why API design matters for large-scale AI search systems
- What defines a design pattern in the context of AI-powered search
- How stateless architecture supports scalability and low-latency performance
- Techniques for enabling explainability and metadata transparency in search results
- How security and access controls preserve data integrity in multi-tenant architectures
- How Mitrix helps organizations design, secure, and operate scalable AI-powered search systems
What are API design patterns for AI-powered search?
API design patterns for AI-powered search refer to well-established, repeatable structures and techniques used to build scalable, adaptable, and intelligent search interfaces that integrate machine learning capabilities. These patterns help engineering teams design APIs that are not only functional but also maintainable, secure, and optimized for user experience.
Let’s have a look at the most notable design patterns for AI-enhanced search APIs.
Key API design patterns overview
1. Separation of concerns: decouple search logic from interface logic
In high-scale AI systems, decoupling the search engine’s core logic from presentation and application interface layers improves maintainability and scalability. APIs should expose a clean contract for query submission, result retrieval, and metadata handling, without entangling UI specifics. This approach allows for independent evolution of the search model and the client-side rendering logic.
Example: Design endpoints like /search, /autocomplete, and /suggestions independently, rather than merging them into a single overloaded call.
2. Stateless requests with tokenized context
To maintain performance across distributed environments, search APIs should remain stateless. User context (e.g., session ID, locale, previous interactions) must be passed via tokens or headers. This facilitates load balancing and reduces server-side memory requirements.
Pattern: Use a context-token header to encapsulate user history, preferences, and prior queries in a securely signed, compressed format.
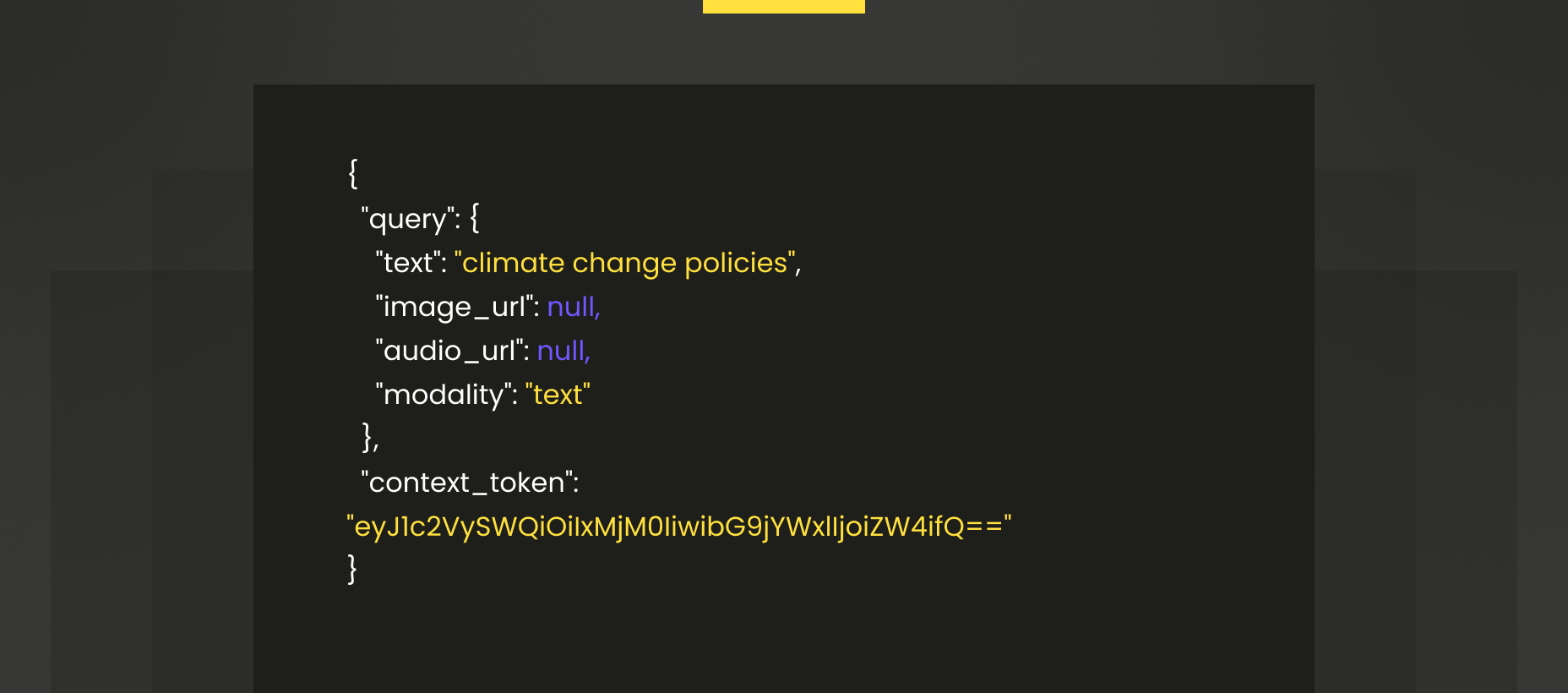
3. Unified query abstraction with multi-modal support
In systems supporting text, voice, and image inputs, a unified query abstraction enables extensibility. The API should standardize input types while preserving modality-specific metadata.
Pattern: Accept a generalized query object with fields like text, image_url, audio_url, and a modality enum.
Here’s an example: Unified Query Object (JSON)
4. Fine-grained relevance tuning via parameters
Expose tunable parameters to clients for refining search behavior, but enforce guardrails to maintain system performance and model integrity. Examples include:
- boost_fields: Increase the weight of specific fields
- rerank_model: Specify optional reranking logic
- filters: Add or remove constraints
These allow downstream systems (e.g., vertical-specific apps) to customize results without modifying core model logic.
5. Pagination and result caching
High-scale systems must minimize redundant computation. Support cursor-based pagination and caching for common queries.
Pattern: Use next_cursor and previous_cursor tokens to paginate results efficiently. Include cache hints in the response header (x-cache-hit, x-cache-ttl).
6. Explainability and metadata-rich responses
Especially in AI-driven systems, search results must include metadata that explains the origin, score, and decision path of the output. This supports debugging, compliance, and trust.
Pattern: Include fields like score, model_version, reasoning_path, and source_type in each result item.
7. RAG-friendly query patterns
For systems leveraging Retrieval-Augmented Generation (RAG), the API must enable structured document retrieval. Responses should separate fact units for easier grounding in generative models.
Pattern: Return documents[] where each item includes title, snippet, relevance_score, and optionally chunk_id or embedding_vector.
8. Event logging for feedback loops
User interaction signals are vital for improving ranking models. Provide a dedicated endpoint to log impressions, clicks, and satisfaction ratings.
Pattern: Create a /search/feedback endpoint that accepts structured interaction logs with fields like query_id, event_type, timestamp, and engagement_score.
9. Backpressure and throttling controls
APIs must guard against overload and misuse. Define fair use limits and expose rate headers.
Pattern: Implement headers like x-rate-limit, x-rate-remaining, and retry-after. Offer exponential backoff guidelines in the documentation.
10. Versioning and experimental flags
Allow safe evolution of models and experiments. Use semantic API versioning (v1, v2) and include experimental flags for testing new behaviors.
Pattern: Provide a features field in the request that accepts flags like use_multilingual_encoder=true, enabling A/B testing without branching endpoints.
11. Hybrid index support and aggregated sources
Modern AI search frequently combines semantic, lexical, and structured search. Design APIs to indicate source types and blend results accordingly.
Pattern: Add a result_type field (e.g., faq, doc, product, profile) and group them in the response for flexible UI rendering.
12. Real-time personalization hooks
Expose personalization hooks to support real-time adjustments without full model retraining.
Pattern: Include headers or optional body fields like user_interest_vector, persona_profile_id, or content_filter_rules that guide relevance scoring dynamically.
13. Health, monitoring, and traceability
Maintain visibility into system health by providing introspection endpoints.
Pattern: Include /health, /metrics, and /trace endpoints with per-query diagnostics and structured latency breakdowns.
14. Security and access control
APIs should support authentication (OAuth2, JWT) and enforce role-based access. Data isolation is essential in multi-tenant systems.
Pattern: Scope queries via tenant ID, ensure PII redaction and implement token-based permissions per route.
15. Documentation and usability by design
Search APIs are often consumed by frontend, mobile, and third-party systems. Documentation should include query examples, error codes, response schemas, and latency expectations.
Pattern: Employ OpenAPI or GraphQL introspection to generate real-time documentation portals.
How Mitrix can help
At Mitrix, we offer AI/ML and generative AI development services to help businesses move faster, work smarter, and deliver more value. We help businesses build and deploy AI agents that are smart and safe. Our team specializes in:
- Custom AI development with hallucination controls
- RAG systems integrated with your internal data
- Workflow automation with audit trails
- Domain-specific model fine-tuning
- Human-in-the-loop pipelines for sensitive tasks
Whether you’re building an AI support agent, a financial analyst bot, or a marketing copilot, we ensure your AI speaks facts, not fiction. Are you ready to put your AI to work without the hallucinations?
Contact us today!
Wrapping up
In short, scalable, AI-enhanced search APIs are the product of well-documented design. Lessons from systems serving over a million users underscore the importance of modular, explainable, and secure interfaces. By incorporating these patterns into the API design lifecycle, engineering teams can accelerate the delivery of robust, adaptive search experiences while preparing for ongoing model iteration and user feedback. The effectiveness of a search API lies not only in its output but in the clarity, resilience, and adaptability of its design.
Equally essential is the foresight to architect APIs with observability and telemetry embedded from the outset. Logging request traces, model decisions, latency metrics, and failure points enable teams to identify degradations, retrain underperforming models, and refine ranking logic in production environments. As AI-driven components evolve, maintaining visibility into how predictions are formed and how users interact with results ensures that the search experience remains relevant, accountable, and aligned with both technical and business goals.

